深度神经网络输出的结果与标注结果进行对比,计算出损失,根据损失进行优化。那么输出结果、损失函数、优化方法就需要进行正确的选择。
常用损失函数
pytorch 损失函数的基本用法
1 | criterion = LossCriterion(参数) |
Mean Absolute Error
torch.nn.L1Loss
Measures the mean absolute error.
Mean Absolute Error/ L1Loss
nn.L1Loss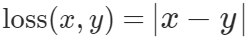
很少使用
Mean Square Error Loss
nn.MSELoss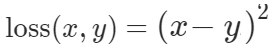
针对数值不大的回归问题。
Smooth L1 Loss
nn.SmoothL1Loss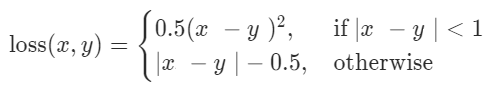
它在绝对差值大于1时不求平方,可以避免梯度爆炸。大部分回归问题都可以适用,尤其是数值比较大的时候。
Negative Log-Likelihood Loss
torch.nn.NLLLoss,一般与 LogSoftmax 成对使用。使用时 loss(softmaxTarget, target)。用于处理多分类问题。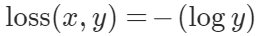
1 | m = nn.LogSoftmax(dim=1) |
Cross Entropy Loss
nn.CrossEntropyLoss 将 LogSoftmax 和 NLLLoss 绑定到了一起。所以无需再对结果使用Softmax
1 | loss = nn.CrossEntropyLoss() |
BCELoss
二分类问题的CrossEntropyLoss。输入、目标结构是一样的。
1 | m = nn.Sigmoid() |
Margin Ranking Loss
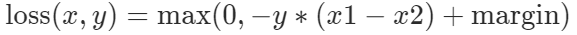
常用户增强学习、对抗生成网络、排序任务。给定输入x1,x2,y的值是1或-1,如果y==1表示x1应该比x2的排名更高,y==-1则相反。如果y值与x1、x2顺序一致,那么loss为0,否则错误为 y*(x1-x2)
Hinge Embedding Loss
y的值是1或-1,用于衡量两个输入是否相似或不相似。
Cosine Embedding Loss
给定两个输入x1,x2,y的值是1或-1,用于衡量x1和x2是否相似。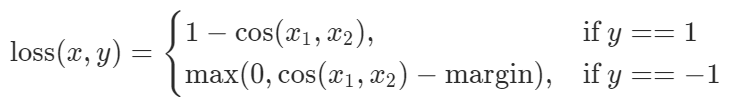
其中cos(x1, x2)表示相似度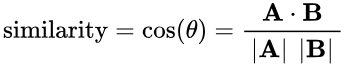
各种优化器
大多数情况Adam能够取得比较好的效果。SGD 是最普通的优化器, 也可以说没有加速效果, 而 Momentum 是 SGD 的改良版, 它加入了动量原则. 后面的 RMSprop 又是 Momentum 的升级版. 而 Adam 又是 RMSprop 的升级版. 不过从这个结果中我们看到, Adam 的效果似乎比 RMSprop 要差一点. 所以说并不是越先进的优化器, 结果越佳.
1 | # SGD 就是随机梯度下降 |