当我在大学中学习线性代数的时候,我不知所云且不以为然。然后随着不断的学习,我发现不懂线性代数是没法在更深的技术领域里混的。比如机器学习、计算机图形学等等,对于其他的科研领域也都是同样的。如果学不好线性代数既不是我的问题,也不是线性代数的问题,那到底是什么问题?最近学些了现代计算机图形学入门-闫令琪 线性代数的本质-3blue1brown 这两个系列视频使我对线性代数多了更多的感性认识,而《实践论》 告诉我们,理性认识是要依赖于感性认识的。传统的线性代数教材则希望构建一套完全自洽的纯粹的数学理论,它不依赖于现实世界的知识。这或许可以满足一些数学家的成就感,但这种马后炮式的“创造”是脱离历史的。线性代数就像其他的学科一样,不可能是仅凭想象产生的,虽然数学家可以伪装成不依赖历史发展而独立自洽,但这除了是一种智力游戏外,对于认识世界、传播知识并没有任何帮助。我们就在这种缺乏感性认识的数学教育中丧失了对数学理论的兴趣,岂不哀哉?
吐槽结束,进入正题。谈谈我此刻对线性代数的理解,探讨一下他的本质到底是什么。我们是否会问自己,加减乘除的本质到底是什么?我们之所以不这么问,是因为我们已经理解了四则运算的本质。我们不会问关于十进制的本质,因为日常生活中已经给我们建立了足够多的经验。但我们在学龄前的阶段,我们则可能对十进制和加减乘除充满了困惑。但我们接触线性代数太晚,我们并没有足够的练习和日常应用使我们建立起感性认识。当我们在商店里消费的时候四则运算不断强化着我们的认知,但线性代数缺少这样的机会。当我们被教授四则运算时,老师把我们当作一个普通的人类,会告诉我们3个苹果+2个苹果=5个苹果,这种现实世界的例子帮助我们更好的理解了四则运算。但当我们学习线性代数时,我们则变成了一个个抽象的理性机器,这个系统只告诉我们各种定义、运算规则,然后要求我们像计算机一样的运行,计算出结果。What are we doing?我们怎么可能不懵圈呢?线性代数就是一个增强版的加减乘除,但没有足够的案例使我们不知道我们的计算究竟代表着什么?AlphaGo就算赢了李世石,但他不知道自己在干什么。我们作为人类的尊严在哪里?我又没控制好自己的情绪,让我们回到正题。《线性代数及其应用》是一本很好的教材,他和国内教材最大的区别就在于“应用”上,这本书中列举了大量的例子来说明线性代数的应用。这本书的开头说道“线性代数是一门语言,必须用学习外语的方法每天学习这种语言”。
鸡兔同笼与线性变换
我们从鸡兔同笼来举个例子。鸡兔同笼是小学阶段的奥数题,也就是在小学的数学语言中,这是一道很难描述的题。到了中学阶段我们可以用未知数x表示鸡的数量,未知数y表示兔的数量,并列出方程。而对于线性代数的语言,我们用向量$$((a),(b))$$表示鸡和兔的数量,如果我们有非常多的未知数,我们不希望定义太多的未知数符号,我们直接用$$x$$表示这个n维变量。我们有一个变换矩阵$$[[1,1],[2,4]]$$ 表示鸡有1个头2只脚,兔有1个头4只脚 。如果有3只鸡5只兔则 $$[[1,1],[2,4]]*[[3],[5]]=[[3*1+5*1],[3*2+5*4]]=[[8],[26]]$$,它代表着我们将一个“鸡兔向量”映射到了“头脚向量”的空间中,共有8只头,26只脚。
我们知道函数是一种映射,$$f(x)=y$$代表将$x$到$y$的映射关系。矩阵乘法叫做线性变换,线性变换是一种函数映射,但函数映射不一定是线性变化。因此线性变换是符合函数的性质的。如果函数是可逆的,则有$$x=f^(-1)(y)$$,同样的,对于矩阵而言,$$若A是可逆的,且Ax=b,则x=A^(-1)b。设A=[[a,b],[c,d]],则A^(-1)=1/(ad-bc)[[d,-b],[-c,a]]$$。
对于鸡兔同笼问题,$$A=[[1,1],[2,4]],则A^(-1)=1/2[[4,-1],[-2,1]]$$。$$当有8头26脚时,x=1/2[[4,-1],[-2,1]]*[[8],[26]]=1/2[[4*8-26],[-2*8+26]]=1/2[[6],[10]]=[[3],[5]]$$,即3只鸡5只兔。最重要的是,这整个计算过程,计算机可以轻松的完成,并且可以用定义标准化的操作,因为操作标准化,计算机可以被设计的更加擅长处理这类操作。这就是线性代数得到广泛应用的一个最重要原因。
线性变换可能进行多次,就像映射可以进行多次一样。因为矩阵的乘法就是一种特殊的函数,函数满足结合律$$g(f(h(x)))=((g @ f)(h(x)))$$,所以矩阵乘法也符合结合律$$A(BC)=(AB)C$$。多次映射之后是一个新的映射,多次变换之后也是一个新的变换,所以我们可以将这些变换矩阵预先乘好,以增加每次计算的效率。也可以将一个复杂变换拆解为多个简单变换,使我们能更好的理解其性质。
我们可以从鸡兔变换到头脚,我们也可以从产量变换到成本收益(这是经济学的应用),我们也可以从速度变换到阻力(这是空气动力学的应用),我们也可以将3D空间变换到3D或2D空间(这是计算机图形学的应用),我们也可以将用户行为维度变换到兴趣标签维度(这是机器学习推荐系统的应用)。这都说明了线性代数是一门“语言”,是一个工具。并不是因为线性代数,所以这些定理存在,而是因为这些规律本身存在,才能有线性代数这门工具。人类是巧妙的“发明”了线性代数,而不是“发现”了线性代数。线性代数这门语言可以使我们避免基本代数语言的变量名爆炸。人类日常语言中有你我他这那等代词,中文有甲乙丙丁这种天干地支可以用作代词,英文则有a,b,cd可以使用。日常的代词使用是随意的,很多时候是不严谨的。代数学的代词在使用前则需要对它进行准确的定义。而线性代数则将最常使用的一些操作提取了出来,使我们免于重复的定义大量性质类似的代词。在线性代数中,鸡兔数量,头脚数量与空间中点的xyz轴位置都是同一种性质的。研究飞机表面的气流的过程包含了反复求解大型的线性方程组$$Ax=b$$,涉及的变量个数达到2百万个。可以说线性代数的发展完全是随着其应用发展的,如果有一本按照历史发展顺序描述线性代数的书,一定可以达到很好的教学效果。
行列式(determinant)
行列式的出现是远早于矩阵的。Determinant是决定的意思,(下文称之为决定值,“行列式”翻译的无味,既没有描述其决定性质,也没有说明其结果是特定的值):决定值是否不为0决定了一个线性方程组是否有唯一解。所谓线性方程组,就是一次方程组。这个结论最早见于《九章算术》(有一种观点认为很多思想是在明朝由中国传至欧洲,而清朝恰好是中国的一个倒退,而欧洲则顺势伪造了一套其文明独立发展的历史叙事,这里不展开描述了)。决定值的这个性质在欧洲由莱布尼茨最早提出(莱布尼茨在中学西传中扮演着重要角色)。高斯首先使用了determinant这个词,他在数论理论中大量用到了决定值。后来这个词就更多的指一个特殊的函数,即某个表达式,因此中文将其翻译为行列式。
观察我们在鸡兔同笼中得出的结论:$$设A=[[a,b],[c,d]],则A^(-1)=1/(ad-bc)[[d,-b],[-c,a]]$$。因此矩阵A当且仅当$$ad-bc!=0$$时存在逆矩阵,我们记为$$det(A)=|A|=|[a,b],[c,d]|=ad-bc$$。我们继续推广研究$3xx3$矩阵,可以得到:
$$|[a,b,c],[d,e,f],[h,i,j]|=a|[e,f],[h,i]|-b|[d,f],[g,i]|+c|[d,e],[g,h]|=aei+bfg+cdh-ceg-bdi-afh=|[a,d,h],[b,e,i],[c,f,j]|$$
对$4xx4$矩阵则有:
$$|[a,b,c,d],[e,f,g,h],[i,j,k,l],[m,n,o,p]|=a|[f,g,h],[j,k,l],[n,o,p]|-b|[e,g,h],[i,k,l],[m,o,p]|+c|[e,f,h],[i,j,l],[m,n,p]|-d|[e,f,g],[i,j,k],[m,n,o]|$$
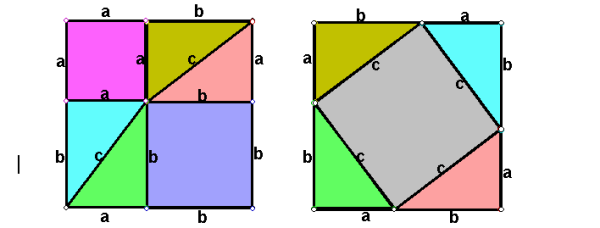
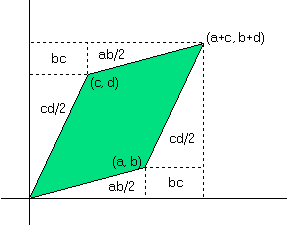
依此类推,决定值的公式是一个递归。决定值的几何意义代表代表$1xx1$矩阵变换后的平行四边形的面积,或者说是矩阵变换后面积的放大倍数,即变换矩阵围成的四边形的面积。简单的证明如下图:$S=(a+c)(b+d)-ab-cd-2bc=ad-bc$。推广到3维则表示变换矩阵的围成的立方体的体积。
如果determinant=0,则说明变换之后由面变为了线,或由体变为了面。而线或面无法再变换回面或体。我们同样以鸡兔同笼问题来举例,我们把题目中的兔换成鸭,则变换矩阵为$$A=[[1,1],[2,2]], det(A)=0$$。这个方程组是没有唯一解的,因为无论鸡鸭的比例如何,头脚的比例都是$1:2$。对于这样的矩阵,我们称他的秩为1,秩代表矩阵的维数。一个二维矩阵,可能秩为1,一个三维矩阵可能秩为2也就是一个面,也可能秩为1也就是一条线,甚至秩为0。
TODO 叉乘表示面积和垂直与平面的向量,特征值与特征向量,表示空间中在线性变换中保持稳定的轴,最小二乘法